임상 성공에 대한 유전적 증거의 영향 정제
Abstract
약물 개발의 비용은 주로 실패에 의해 좌우되며, 임상 프로그램 중 약 10%만이 승인을 받는 것으로 나타났습니다. 이전 연구에서는 인간 유전학적 증거가 임상 개발에서 승인까지의 성공률을 두 배로 높인다고 추정했습니다. 이번 연구에서는 지난 10년 동안 유전 증거의 증가를 활용하여 임상 성공과 실패를 구분하는 특성을 더 잘 이해하고자 했습니다. 유전적 지지를 받는 약물 기전의 성공 확률은 그렇지 않은 경우보다 2.6배 더 높은 것으로 추정됩니다. 이러한 상대적 성공은 치료 영역과 개발 단계에 따라 다르며, 인과 관계가 있는 유전자에 대한 확신이 커질수록 향상되지만, 유전적 효과 크기, 소수 변이 빈도 또는 발견 연도에는 크게 영향을 받지 않습니다. 이 결과는 우리가 보다 효과적인 약물의 타겟을 발견하기 위한 유전적 통찰의 정점에 이르지 못했음을 시사합니다.
Figures
Impact of genetic evidence characteristics on RS
– 약물 개발 파이프라인을 특징짓기 위해, Citeline Pharmaprojects 데이터베이스에서 2000년 이후에 추가된 단독 치료 프로그램을 필터링했습니다.
– 이 프로그램들은 최고 단계에 도달했으며, 인간 유전자 타겟(주로 약물 표적 단백질을 인코딩하는 유전자)과 의학 주제 표제어(MeSH) 온톨로지로 정의된 적응증이 할당되었습니다. 29,476개의 타겟-적응증(T–I) 쌍이 생성 되었습니다.
– 다양한 출처에서 얻은 인간 유전적 연관성은 총 81,939개의 고유한 유전자-형질(G–T) 쌍을 포함하고 있었으며, 이 형질들 역시 MeSH 용어로 매핑되었습니다.
– 이 두 데이터 세트의 교차 분석 결과, 적응증과 형질 MeSH 용어의 유사도가 0.8 이상인 2,166개의 T–I 및 G–T 쌍(7.3%)이 도출되었습니다. 이러한 T–I 쌍들은 유전적 지지를 받고 있다고 정의되었습니다.
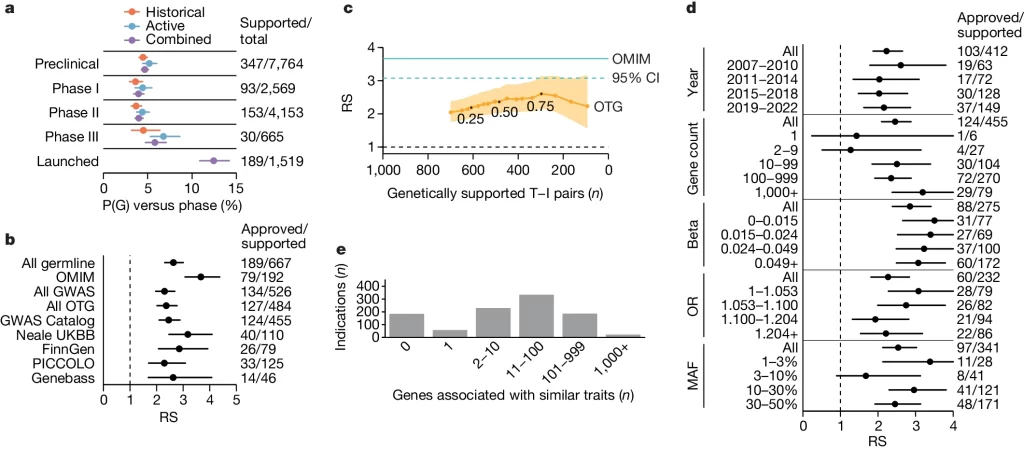
Fig. 1. 유전적 증거 특성이 RS(상대적 성공률)에 미치는 영향
(A) 약물 개발 단계 별 T-I 쌍 중 유전적 증거 특성이 있는 비율
(B) 인간 유전 연관성 출처에 따른 1상부터 출시까지의 상대적 성공(RS)의 민감도
(C) OTG 연관성 중 L2G 비율 임계값에 따른 RS의 민감도. 최소 L2G 비율 임계값은 0.1부터 1.0까지 변화되며 (라벨); RS(세로축)는 OTG로부터 유전적 지지를 받는 임상(1상 이상) 프로그램 수(가로축)에 대해 그래프로 나타납니다.
(D) OTG GWAS 지지를 받는 T–I 쌍에 대한 RS의 다양한 변수에 대한 민감도
(E) Pharmaprojects에서 개발된 적응증의 수(세로축)과 그 적응증과 유사한 특성을 가진 유전자 수(가로축)
[Fig 1A] 유전적 지지를 받을 확률, 즉 P(G)는 역사적이거나 현재 진행 중인 임상 개발 단계의 타겟-적응증(T–I) 쌍보다 이미 출시된 T–I 쌍에서 더 높았습니다. 즉, 출시된 약물은 그 효과가 유전적 연구를 통해 더 잘 입증되었다는 것을 나타냅니다. 이는 유전적 지지가 높은 약물이 임상에서 성공할 확률이 더 높음을 시사합니다.
[Fig 1B] 상대적 성공(RS)을 유전적 지지를 받는 성공 확률 P(S)과 유전적 지지를 받지 않는 경우의 성공 확률의 비율로 정의했습니다. RS는 Online Medndelian Inheritance in Man (OMIM) (RS=3.7)로 가장 높았으나, 이는 rare disease의 경우 causal gene이 더 쉽게 할당 되기 때문임. 모든 경우 RS는 2보다 컸음.
[Fig 1C] Open Targets Genetics (OTG)의 연관성 분석에서 상대적 성공(RS)은 변이에서 유전자로의 매핑 신뢰성에 민감하게 반응하는 것으로 나타났습니다. 여기서 말하는 ‘변이에서 유전자로의 매핑’이란 특정 유전자 변이가 질병 발생에 미치는 영향을 정확하게 어떤 유전자와 연결짓는지를 의미합니다. 이 연구에서는 locus-to-gene (L2G) 점수의 최소 비율을 통해 이 매핑의 신뢰성을 반영하고 있습니다. 즉, L2G 점수가 높을수록 해당 유전자와 질병 간의 연관성에 대한 신뢰도가 높다는 것을 의미하며, 이러한 신뢰도는 약물 개발에서의 성공 확률(RS)에 영향을 미치는 중요한 요소입니다. 이는 멘델리안 조건과 GWAS 간의 접근 방식 차이가 유전적 지지의 강도를 평가하는 데 중요한 역할을 한다는 것을 시사합니다.
[Fig 1D]
1. GWAS를 통해 인간 유전적 지지를 처음으로 받은 T–I 쌍의 연도 : 처음 발견된 변이가 effect가 클 것이기에 후에 발견된 변이들은 가치가 적다는 가설에 반박),
2. 같은 특성과 유전적 연관성을 보이는 유전자 수 : 연관된 유전자 수가 증가할수록 상대적 성공(RS)은 유전자 당 0.048씩 증가하는 경향이 있었고, 이는 통계적으로 유의미한 결과였습니다(P = 0.024). 이러한 결과는 유전적 지지를 받는 성공적인 프로그램이 다른 프로그램에 영감을 주었기 때문이라기보다는, 대부분의 유전적 지지가 회고적으로 발견되었기 때문입니다. 유전적 증거에 의해 전망적으로 동기 부여된 약물 프로그램의 소수 사례는 주로 멘델리안 질환을 위한 것이었습니다.
3. 정량적 특성에 대한 효과 크기(베타)의 사분위수, 4. 사례/대조군 특성에 대한 효과 크기(오즈 비율, OR)의 사분위수, 5. 소수 변이 빈도의 크기 순서 통계 : 추정된 효과 크기와 소수 변이 빈도에 대한 통계적으로 유의미한 연관성은 없었습니다(P = 0.90 및 0.57, 정량적 및 이진 특성에 대해 각각; P = 0.26). 이는 더 큰 규모의 GWAS가 성공적인 타겟에 대한 지지를 계속 발견할 수 있음을 시사합니다.
Differences in RS between therapy areas and the number and diversity of indications per target
– 이전에는 유전적 지지를 받는 약물 기전의 승인 비율이 치료 영역별로 큰 차이를 보였지만, 성공 확률에 대한 영향은 조사하지 않았습니다.
– 최근 연구에서 1상에서 출시까지의 상대적 성공(RS)을 분석한 결과, 모든 치료 영역에서 RS가 1 이상이며, 17개 중 11개 영역에서는 2를 넘는 것으로 나타났습니다. 특히 혈액학, 대사, 호흡기, 내분비 영역에서는 3 이상의 높은 RS를 기록했습니다.
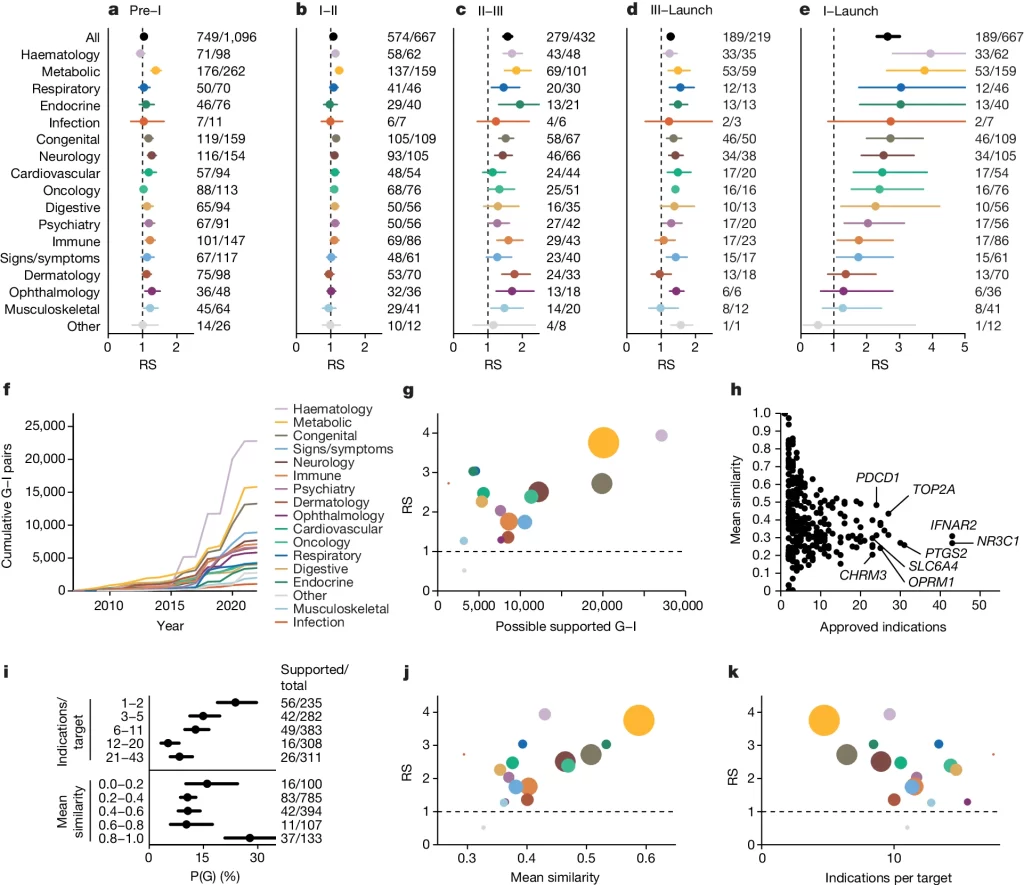
Fig. 2. 치료 영역 간 RS의 차이와 타겟별 적응증 수 및 다양성의 차이
(A-E) 임상 단계별 RS 차이를 질환의 종류별로 나타냄.
(F) 각 치료 영역에서 시간에 따라 축적된 유전적 발견에 따른 유전적 지지를 받는 G–I 쌍의 누적 수
(G) 치료 영역별로 가능한 지지받는 G–I 쌍의 수(x축)에 따른 RS(상대적 성공, y축)를 나타내며, 점은 패널 a-e와 같은 색으로 표시되고, 적어도 1상에서 유전적 지지를 받는 T–I 쌍의 수에 따라 크기가 조정
(H) 승인된 약물 타겟별로 출시된 적응증의 수와 그 적응증의 유사성 비교
(I) 유전적 지지를 받는 출시된 T–I 쌍의 비율, P(G)
(J) 치료 영역별 타겟당 출시된 적응증의 평균 유사성(x축)에 따른 RS(상대적 성공, y축)
(K) 타겟당 출시된 적응증의 평균 수(x축)에 따른 RS(y축).
[Fig 2G] 유전적 증거에 의해 지원받는 유전자-적응증(G–I) 쌍이 많은 치료 영역에서 상대적 성공(RS)이 유의미하게 높았다는 사실을 발견했습니다(ρ = 0.71, P = 0.0010; Fig. 2g). 하지만 호흡기와 내분비 영역은 연관성이 적음에도 불구하고 높은 RS를 기록하여 주목할 만한 예외로 나타났습니다.
[Fig 2H] 질병을 개선하는 약물의 타겟은 특정 질병에 특화될 가능성이 높고, 증상을 관리하는 약물의 타겟은 여러 적응증에 걸쳐 사용될 가능성이 높다고 추론했습니다. 출시된 타겟-적응증(T–I) 쌍은 소수의 타겟에 집중되어 있었으며, 450개의 출시된 타겟 중 42개가 10개 이상의 출시된 적응증을 가지고 있었고, 이는 출시된 T–I 쌍 1,806개 중 713개(39%)를 차지했습니다. 출시된 적응증의 수와 그 적응증의 평균 유사성(낮을수록 다양한 질병에 쓰인다는 의미)은 역상관 관계를 보였습니다.
[Fig 2I-2K] 출시된 적응증이 적을수록, 그리고 타겟의 출시된 적응증의 유사성이 클수록 유전적 지지를 받을 확률이 증가하였으며 RS또한 증가하는 경향을 보였습니다. 이 결과는 특정 질병에 맞춰 개발된 약물이 유전적 지지를 더 많이 받으며, 치료 효과나 약물 개발의 성공률에 긍정적인 영향을 미칠 수 있음을 시사합니다.
Clinical investigation of drug mechanisms with genetic evidence.
– 연구 방법에 따르면, 유전적 지지를 받는 모든 G–I(유전자-적응증) 관계 중 임상적으로 탐색된 비율은 1.1%에 불과합니다. 가장 유사한 적응증으로 범위를 한정했을 때는 이 비율이 2.1%로 증가합니다.
– 대부분의 단백질이 전통적으로 ‘약물로서 개발이 어렵다'(undruggable)고 여기기에 유전적 지지를 받는 G–I 쌍 중 최소 1상까지 개발된 비율을 치료 영역별로 다양한 약물 가능성 클래스와 관련된 단백질 families을 고려하여 조사했습니다.
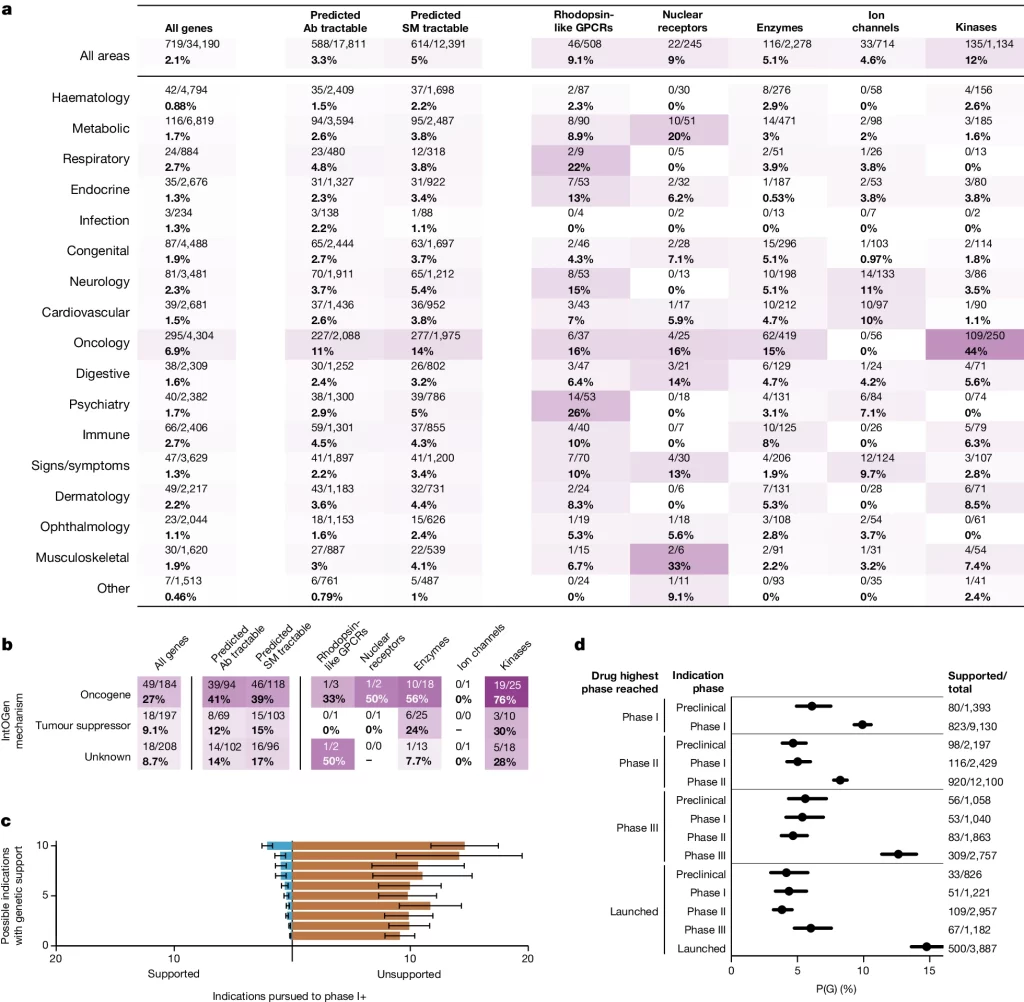
Fig. 3.유전적 증거를 바탕으로 한 약물 기전의 임상 조사
(A) 치료 영역별(세로축) 및 유전자 목록별(가로축)로 최소 1상까지 개발된 유전적 지지를 받는 T–I 쌍의 비율을 나타내는 히트맵.
(B) 패널 a와 비슷하지만, 이번에는 germline 세포 계열의 유전적 자료가 아닌 IntOGen에서 제공하는 유전적 지지를 바탕으로 하며, 유전자의 효과 방향을 IntOGen 기준으로 그룹화(세로축)
(C) 적어도 하나의 유전적으로 지지받는 적응증이 있고, 적어도 하나의 적응증에 대해서 1상에 도달한 타겟들에 대해, 유전적으로 지지받는 적응증(왼쪽)과 지지받지 못한 적응증(오른쪽)의 평균 수(x축)를 유전적으로 지지받을 가능성이 있는 적응증의 수(y축)에 따라 구분하여 나타냄
(D) 유전적 지지를 받는 D–I(약물-적응증) 쌍의 비율, P(G) (x축)을 각 D–I 쌍이 도달한 단계(내부 y축 그룹화)와 해당 약물이 어떤 적응증에 대해 도달한 최고 단계(외부 y축 그룹화)에 따라 나타낸 함수
[Fig. 3A] 치료 분야 내에서, 유전적 근거를 갖고 있는 종양학 분야의 kinase들이 가장 많이 연구되었습니다. 유전적으로 지지받는 모든 G–I 쌍 250개 중 109개(44%)가 최소 1상까지 진행되었습니다. 또한 정신 질환 치료를 위한 GPCR(G 단백질 연결 수용체)도 눈에 띄는데, 53개 중 14개(26%)가 1상 이상으로 진행되었습니다
[Fig. 3B] 일부 타겟 유형은 작용제(agonist)보다는 길항제(antagonist)에 의해 더 쉽게 조절될 수도 있기 때문에, 우리는 타겟별로 그룹화를 하고 종양 억제 유전자와 종양 유전자의 효과 방향에 따라 인간 유전적 증거를 조사했습니다. 이를 통해 유전적으로 지지받는 적응증에 대해 최소 1상까지 진행된 유전적으로 지지받는 타겟의 대다수가 있는 몇몇 하위 계층을 확인했습니다. Oncogene kinase들이 가장 많은 관심을 받았으며, 25개 중 19개(76%)가 1상에 도달했습니다.
[Fig. 3C] 약물로서 개발 가능성이 명백한 단백질에 초점을 맞추기 위해, 분석을 (1) 최소 1상에 도달한 프로그램이 있는 타겟과 (2) 하나 이상의 유전적으로 지지받는 적응증이 있는 타겟으로 제한했습니다. 자격을 갖춘 1,147개의 타겟 중에서 단 373개(33%)만이 하나 이상의 지지받는 적응증에 대해 추진되었습니다(Fig. 3c). 그리고 이 중 대부분의 타겟(307개, 27%)은 유전적 지지가 있는 적응증과 없는 적응증 모두에 대해 추진되었습니다. 전반적으로, 개발 노력의 압도적인 다수가 지지받지 않는 적응증을 위해 이루어졌으며, 그 비율은 17:1입니다.
[Fig. 3D] 우리는 유전적 지지가 어떤 적응증이 파이프라인에서 가장 멀리 진행될지를 예측하는지를 조사했습니다. 활성 및 과거 프로그램을 약물-적응증(D–I) 쌍으로 그룹화하여, 유전적 지지를 받는 적응증이 파이프라인의 더 후반 단계로 진행될 오즈가 82% 더 높다는 것을 발견했습니다.