
규모가 크고 사용자 지시를 잘 따르는 언어 모델의 신뢰성이 낮아진다

Abstract
대형 언어 모델(Large Language Models; LLM)이 더욱 커지고 사용자 지향적으로 설계될수록 신뢰성이 낮아질 수 있다는 연구 결과가 발표되었습니다. 기존에는 모델의 크기, 데이터 양, 계산 자원을 지속적으로 확장(scale up)하고, 후처리(post-filtering), 미세 조정(fine-tuning), 인간 피드백(human feedback) 등을 통해 모델을 더욱 강력하고 사용하기 쉽게 만드는 방법이 주로 사용되었습니다.
그러나 이 연구에서는 이러한 확장과 개선이 오히려 모델의 신뢰성을 저하시킬 수 있다는 점을 밝혔습니다. 여러 언어 모델 군을 대상으로 난이도 일치성(difficulty concordance), 과제 회피(task avoidance), 프롬프트 안정성(prompting stability)의 관계를 연구했습니다. 그 결과, 인간 참가자에게 쉬운 과제는 언어모델에게도 해결하기 쉬웠습니다. 하지만 쉬운 문제를 푸는 데 규모가 큰 모델들이 오히려 오류를 더 자주 범하거나, 인간 감독자가 오류를 놓치기 쉬운 상황을 만들어낸다는 점을 발견했습니다.
또한 초기 모델들은 사용자 질문을 회피하는 경향이 있었으나, 확장되고 개선된 모델들은 겉보기에는 타당하지만 실제로는 잘못된 답변을 훨씬 더 자주 제공하게 되었으며, 특히 어려운 질문에서의 오류는 인간 감독자들이 자주 간과하는 경우가 많았습니다. 나아가, 동일한 질문에 대한 다양한 자연스러운 표현을 제공하는 면에서 판단 가능한 응답의 안정성은 모델 확장 및 개선을 통해 향상되었으나, 질문의 난이도에 따라 여전히 변동성이 존재함을 발견했습니다.
이러한 발견은 범용 인공지능의 설계 및 개발에 근본적인 변화가 필요함을 강조합니다. 특히 오류의 예측 가능한 범위가 매우 중요한 고위험(high-stakes) 분야에서는 단순한 모델 확장이나 개선만으로는 충분하지 않으며, 신뢰성을 보장하기 위한 새로운 접근 방식이 요구됩니다.
Figures
Reliability fluctuations
l LLM이 발전하여 다양한 분야에서 쓰이지만 실수가 잦습니다.
l LLM의 신뢰 있는 사용을 위해서는 유저가 올바른 대답을 지도해야 하는데, 그 가능성이 더 커지는 만큼 LLM의 신뢰 있는 답변이 어떻게 발전되었는지 분석할 필요가 있습니다.
l Reliability는 언어 모델의 오류가 예측 가능하고 사용자가 이를 이해하여 적절히 대응할 수 있는 정도를 말합니다.
l Figure 1은 초기 LLM 이후에 개발된 정교한(shaped-up) 언어 모델들이 다양한 벤치마크에서 프롬프트 변화에 얼마나 안정적이고 정확하게 반응하는지를 주요 지표로 보여줍니다. 이를 통해 모델의 성능 향상과 그에 따른 한계점을 시각적으로 비교 분석하기 위해 제작되었습니다.

![[fig.1]ezv](https://scienceeasyview.com/wp-content/uploads/2024/09/fig.1ezv.png)
[Figure 1] GPT (OpenAI), LLaMA (Meta) 및 BLOOM (BigScience)의 주요 특징.
주요 LLM 모델들의 특징을 정리한 것으로, 초기(raw) 모델과 정교한(shaped-up) 모델이 다양한 응답 유형(정확(c; correct), 회피(a; avoidant), 오류(i; incorrect))에서 어떻게 다르게 군집화 되는지를 보여줍니다. 이를 통해 shaped-up 모델들이 프롬프트 변화에 더 안정적이고 정확하게 반응하지만, 인간의 난이도와의 일치성은 낮고 전반적인 실패 빈도가 높음을 시각적으로 비교 분석하고자 제작되었습니다.
Main experiment
이 연구에서는 대형 언어 모델(LLM)의 신뢰성이 시간에 따라 어떻게 변하는지를 분석하기 위해 체계적인 실험을 설계했습니다.
다음과 같은 신뢰성 분석의 지표를 측정합니다.
l Task Avoidance: 모델이 답변을 회피하거나 오류를 피하려는 경향.
l Prompting stability: 사용자가 같은 질문을 여러 가지 다른 방식으로 표현했을 때, 모델이 일관되게 정확한 답변을 제공하는 능력.
l Difficulty concordance: 문제의 난이도에 대해 사람과 모델이 얼마나 동일하게 느끼는 지의 정도.
실험은 다음과 같은 주요 단계와 요소로 구성됩니다.
(1) 다음과 같은 응답 유형이 있습니다.
l 정확한 응답 (Correct; C)
l 오류 응답 (Incorrect; I)
l 회피 응답 (Avoidant; A)
(2) LLM과 유저 사이의 관점 차이를 설명하기 위해 인간 대상의 연구도 병행했습니다.
l S1 (체감 난이도): 설정한 난이도 지표가 인간의 실제 난이도 인식과 얼마나 일치하는지 평가.
l S2 (정확성): 인간이 모델의 응답을 얼마나 정확하게 평가하고, 오류를 보완할 수 있는지 탐구.
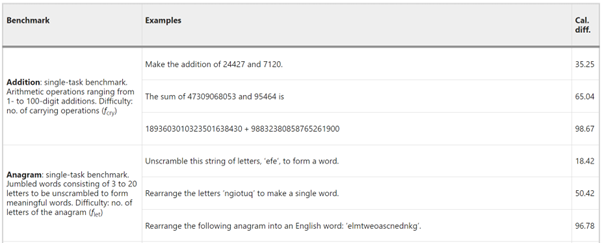
(3) LLM은 총 다섯 가지의 영역으로 평가되었습니다. [Table 2]
l 단순 수리 능력 (‘addition’)
l 어휘 재배열 (‘anagram’)
l 지리적 지식 (‘locality’)
l 다양한 과학 기술 (‘science’)
l 정보 중심의 변환 (‘transforms’)
Results

![[fig.2]ezv](https://scienceeasyview.com/wp-content/uploads/2024/09/fig.2ezv.png)
[Figure 2] 증가하는 난이도의 문제에 대한 GPT 및 LLaMA 모델의 반응
GPT와 LLaMA 계열의 모델들 중 선택된 몇 가지 모델의 결과를 보여줍니다. 이 모델들은 점차 규모가 확장되었으며, 오른쪽에는 형태가 개선된(shaped-up) 모델들이 배치되어 있습니다.
각 그래프는 체감 난이도(x축), 비율(y축), 그리고 색깔 별로 응답의 유형을 나타냅니다. (빨강: i, 하늘: a, 남색: c)
l 다섯 가지 도메인에서의 성과를 비교한 결과, 마지막 열에 가까워질수록 규모가 확장되고 형태가 개선된 모델들의 정답률이 증가하는 것을 확인할 수 있습니다. 그러나 완전한 concordance가 있다고 보기 어렵습니다.
l 인간이 정의한 질문의 난이도에 따라, 인간이 어렵다고 느끼는 질문을 LLM 모델도 어렵다고 느낀다고 볼 수 있습니다. 하지만 매우 쉬운 문제라고 해도 완전히 신뢰할 수 있는 결과를 얻을 순 없었습니다.
l 모델 종류 기준으로 보았을 때, 전반적으로 incorrect한 결과의 비중이 오른쪽으로 갈수록 비약적으로 늘어납니다. 특히 shaped-up 모델에서 avoidance가 일어난다고 명확히 말할 수 없을 정도입니다.
l 한 모델을 기준으로 보았을 때, 난이도가 증가할수록 avoidance가 증가하지 않습니다.

![[fig.3]ezv](https://scienceeasyview.com/wp-content/uploads/2024/09/fig.3ezv.png)
[Figure 3] 인간 설문 연구 S2에 따른 난이도별 검토 오류(supervision error) 유형의 변화
검토 오류(supervision error)는 모델의 대답이 정확한지 부정확한지 사람이 판별해 내지 못한 경우를 말합니다. 여기서는 모델의 대답이 인간에게 어떻게 받아들여지는지에 대해 연구했습니다.
각 그래프는 난이도(x축), 비율(y축), 그리고 색깔 별로 응답의 유형을 나타냅니다. (남색: i~a, 주황: i~c, 하늘: i~I, 노랑: i~unsure)
* 그래프 해석 예시(주황색): 틀린 답을 한 LLM에 사람이 맞다고 한 경우.
l 전체적으로, 문제의 난이도에 따라 모델의 반응이 달라져서 이를 검증하는 사용자에게 영향을 미칩니다.
l 해당 실험의 결과, 사람이 모델의 실수를 잡아내지 못하는 경우가 많다고 볼 수 있습니다. 즉, 인간의 감독이 모델의 신뢰성 부족을 보완하지 못하는 경우가 많다는 것을 보여줍니다.
l 이상적으로는 쉬운 문제일수록 모델이 덜 틀리고 사람이 잘 확인할 수 있어야 하지만, 실제로는 쉬운 덧셈 문제와 일부 단어 문제에서만 이런 상황이 잘 작동했습니다. (이는 이 두 문제는 검증하기가 비교적 쉬웠기 때문입니다.)

![[fig.4]ezv](https://scienceeasyview.com/wp-content/uploads/2024/09/fig.4ezv.png)
[Figure 4] LLaMA 및 BLOOM 계열 LLM 및 비지도 GPT 모델의 척도 분석
FLOP(floating-point operations)에 대해 로그 단위를 측정합니다. 각 지표는 avoidance(왼쪽 위), incorrectness(왼쪽 아래), 그리고 ultracrepidarianism(i/a+i; 회피 및 오류 반응 중 오류 반응의 비율, 즉 모르는 분야에 대해 자신감 있는 답을 제공하는 것)을 중점으로 측정했습니다.
l Shaped-up 모델들은 raw 모델에 비해 avoidance가 현저히 낮습니다. 하지만 오류율은 더 높아집니다.
l 모델의 규모가 커짐에 따라 정확성은 증가하지만, 오류율은 감소하지 않습니다. 또한 예상과 다른 결과로, 일반적으로는 모델의 규모가 커지고 성능이 향상되면 오류율이 감소할 것으로 기대되지만, raw 모델에서는 그 반대로 오류율이 증가하는 것을 확인했습니다.
l Shaped-up 모델들은 좀 더 ultracrepidarian한 답변을 잘 내놓습니다.
이 연구에서 LLM의 신뢰성이 유저와 어떻게 상호작용하는지를 보았을 때, 주요 발견은 다음과 같습니다.
l Difficulty concordance (F1): 모델은 사람이 어렵다고 느끼는 문제에서 더 많이 틀리지만, 쉬운 문제에서는 여전히 오류가 많습니다.
l Task Avoidance (F2): 모델이 질문을 회피하지 않고 답변을 시도할수록 오류가 증가합니다. 특히, 난이도가 높아져도 회피가 늘어나지 않아 사용자가 오류를 쉽게 인식하지 못합니다.
l Prompting stability (F3): 모델이 더 커지고 개선되었음에도 불구하고, 다양한 질문 방식에 따라 여전히 민감하게 반응합니다. 일부 프롬프트는 특정 난이도에서만 잘 작동하고, 다른 난이도에서는 오류가 더 많이 발생합니다.
Disscussion
이 논문에서는 두 가지 인간 연구를 수행했습니다. 첫 번째 연구는 참가자들이 입력에 응답할 때 인지된 난이도와 실제 난이도가 얼마나 일치하는지 조사하여, difficulty concordance가 difficulty proxies와 상관관계가 있는지 확인했습니다. 두 번째 연구는 참가자들이 모델의 출력을 감독하거나 검증하여, 인간이 잘못된 응답을 올바른 것으로 받아들이는지를 조사했습니다. Difficulty concordance를 최대화하고 인간 검증 과정에서 발생할 수 있는 incorrect-to-correct errors를 줄이기 위해서는 모델을 훈련하고 shaping up할 때 이를 손실 함수에 반영해야 합니다. 이를 위해 인간의 난이도 기대치와 출력 감독에 대한 더 큰 데이터셋을 구축하는 집단적인 노력이 필요합니다. 이러한 데이터는 기존의 인간 피드백보다 더 정교한 AI를 사용하여 감독자를 훈련시키는 데 활용될 수 있습니다. 특히, 의료 등 중요한 분야의 shaped-up 모델은 거부 옵션을 포함하거나 외부 AI 감독자와 결합하여 task avoidance를 촉진할 수 있습니다. 이러한 개입은 LLM이 신뢰성을 보장하는 인간과 유사한 특성을 갖추도록 해야 합니다. 그러나 이러한 작업이 완료되지 않은 상태에서 LLM의 사용이 일반 대중에게 널리 퍼져 있는 점을 감안할 때, 특히 진실이 중요한 분야에서는 인간의 감독 행위에 의존하는 것은 위험하다는 점을 경고하고자 합니다.
해당 분석에는 몇 가지 한계가 있습니다. 첫 번째는 대부분 비전문가 참가자를 모집했다는 점으로, 일부 벤치마크에서 높은 난이도 점수가 일반 대중이 해결할 수 없는 질문이 많기 때문입니다. 두 번째는 ‘자연스러운’ prompts 샘플을 다양한 출처에서 수집했지만, 실제 시나리오에서 특정 prompt가 얼마나 자주 사용되는지 알 수 없었습니다. 마지막으로, 특정 궤적을 가진 모델군만을 다루어, 외부 도구를 사용하거나 정교한 추론 기법을 사용하는 LLM은 제외했습니다.
GPT 계열은 최근 몇 년간 성능에서 선두를 달리며 OpenAI가 다른 언어 모델 개발에 큰 영향을 미쳤습니다. 반면, LLaMA와 BLOOM은 보다 개방적이고 체계적인 모델 라인업을 통해 scaling과 shaping up을 분리할 수 있으며, 우리의 방법론과 코드를 사용한 점진적 분석의 길을 열어줍니다. 이러한 모델들의 신뢰성 문제를 강조하고 새로운 분석 도구를 도입하는 것은 매우 중요하며, 다른 연구자들이 향후 scaled-up, shaped-up 모델을 탐구할 수 있도록 도와줍니다.