
대형 중성 아미노산 수준의 주산기 신경 흥분성과 생존 조절

Abstract
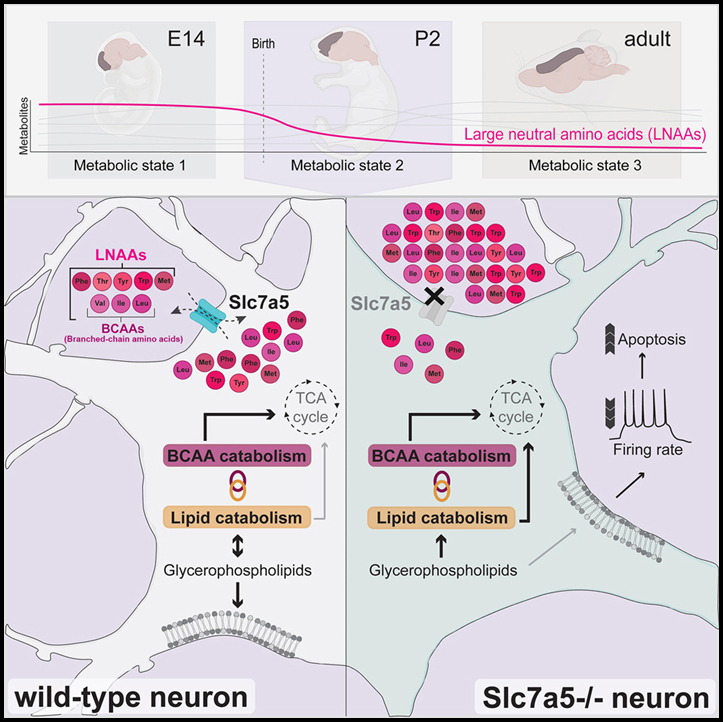
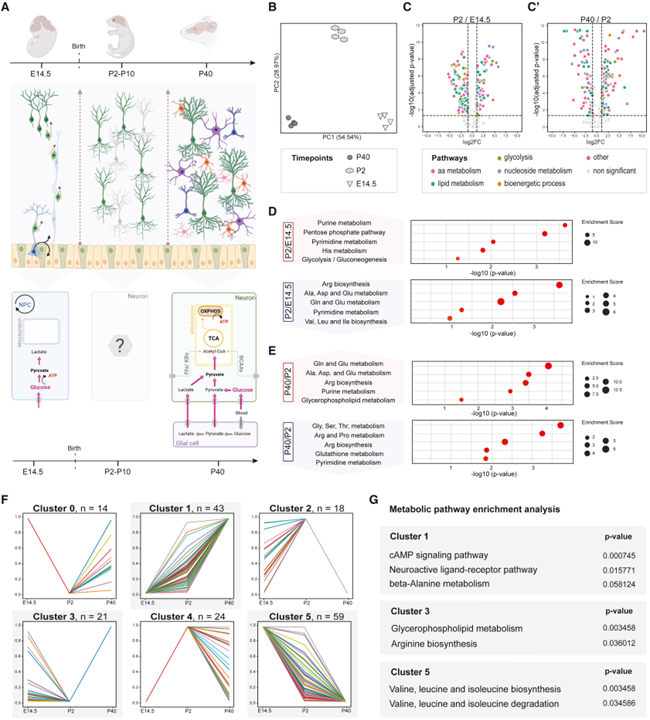
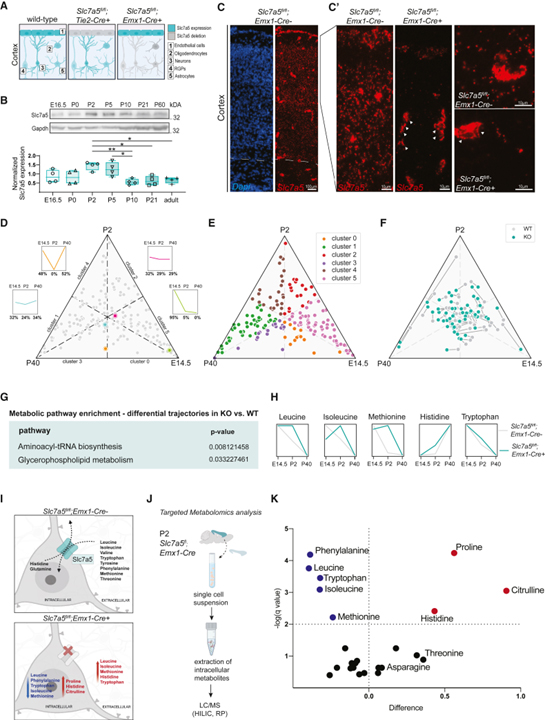
발달 과정에서 신경 세포가 겪어야 하는 중요한 대사 변화와 이 프로그램의 일시적 변화가 뇌 회로와 행동에 어떻게 영향을 미칠 수 있는지에 대해서는 알려진 바가 거의 없습니다. 대사적으로 필수적인 대형 중성 아미노산 (LNAA)의 운반체인 SLC7A5의 돌연변이가 자폐증을 유발한다는 발견에 영감을 받아 우리는 여러 발달 단계에 걸쳐 대뇌 피질의 대사 상태를 연구하기 위해 대사 프로파일링을 사용했습니다.
우리는 전뇌가 발달 전반에 걸쳐 중요한 대사 리모델링을 겪는다는 것을 발견했으며 특정 대사산물 그룹은 단계별 변화를 보여 이 대사 프로그램을 방해하면 어떤 결과가 발생할지 확인했습니다. 신경 세포에서 Slc7a5 발현을 조작함으로써 우리는 LNAA와 지질의 대사가 피질에서 상호 연결되어 있음을 발견했습니다. 뉴런에서 Slc7a5의 결실은 출생 후 대사 상태에 영향을 미쳐 지질 대사의 변화를 초래합니다. 또한 신경 활동 패턴의 단계 및 세포 유형별 변경을 유발하여 장기적인 회로 기능 장애를 초래합니다.
Figure

[Figure 1] 3,202 1kGP sample high-coverage WGS data에서의 SNV/INDEL 발견
(A) 성별 및 super-population에 따라 나누어 분류한 샘플 수입니다.
기존: 2,504 1kGP samples / 신규: 698개의 sample 추가
(B) 3,202개의 샘플에서 발견한 코호트 단계 alternative allele counts. AF bins(Allele frequency 구간)로 나누었습니다.
Novel / known: dbSNP build 155(해당 논문 이전의 1000 Genome Project 버전)에 존재하지 않는/존재하는 sites입니다.
AF는 서로 연관되어 있지 않은 2,504개의 샘플을 기준으로 추정했습니다.
Pie chart: super-population ancestry에 따른 novel variants의 구분. 회색 부분은 해당 샘플이 하나 이상의 super-population에 속함을 의미합니다.
(C) 각 genome 별로 small variant loci의 개수를 세었습니다. 인구를 기준으로 나누었습니다.
(D) 예측된 functional SNVs, INDELs(상염색체 내)입니다.
위: 코호트 단계에서 variants의 수를 센 막대그래프, 그리고 샘플 단계에서 그 분포를 box plot으로 함께 나타낸 그림입니다. 2,504개의 서로 관련 없는 샘플을 대상으로 진행했습니다.
중간: 예측된 functional sites 중 rare(MAF(Minor Allele Frequency) ≤ 1%) SNVs & INDELs의 비율을 나타냅니다. 해당 논문에서 강조하는 부분으로, 예측된 functional SNV 중 86%~97%, INDEL 중 67% ~ 95%가 rare genetic variants로 분류되었습니다. 이 중 SNV는 1~7%가, INDEL은 5~32%가 novel하게 분류되었습니다.
(E) GIAB(Genome in a Bottle: Consortium) truth set v3.3.2에 의존하여 계산된 Precision vs Recall. Genome의 easy / difficult한 region 으로 나누었습니다.
Easy & difficult region은 GIAB에 의해 정의되었으며, difficult region이 전체 genome의 20%에만 해당하지만, 높은 비율의 multiallelic states를 포함하여 변이의 주요 사이트라고 볼 수 있습니다. 뿐만 아니라, INDEL loci도 다수 포함하고 있어 특정 allele이 변이되었을 뿐만 아니라 추가 혹은 제거되어 있을 확률이 높습니다.
(Super-population ancestry 표기: EUR(유럽인), AFR(아프리카인), EAS(동아시아인), SAS(서아시아인), AMR(아메리카인))

[Table 1] 코호트 & 샘플 단계 각각 high-coverage 1kGP call set의 variant count에 대한 요약 테이블
(용어) Super-population ancestry 표기: EUR(유럽인); AFR(아프리카인); EAS(동아시아인); SAS(서아시아인); AMR(아메리카인). Small variant 종류 표기: SNV(Single Nucleotide Variant); IN-DEL(short deletion); IN-INS(short insertion); Structural Variant 종류 표기: DEL(deletion); DUP(duplication); mCNV(multiallelic CNV); INS(insertion); INV(inversion); CPX(complex SV); CTX(inter-chromosomal translocation)

[Figure 2] 3,203 1kGP 샘플의 high-coverage WGS data에서의 SV 발견
(A-C) 각 SV class의 (A) 수, (B) 크기에 대한 분포, (C) 대립 유전자 빈도(allele frequency) 분포표
(D-F) SV의 sample count 당 평균. (D) variant class, (E) ancestral population, (F) 유전을 주고받는 비율.
(F)에서, child inheritance rate는 아이가 가지고 있는 SV 중 부모에게 물려 받은 비율을 의미합니다. Parental transmission rate는 부모의 genome에서 아이에게 전달되는 비율을 의미합니다. 해당 figure에 표현된 부분은 모두 informative SV이며, 한 명의 부모에게서만 이형(heterozygous)인 조건을 가지고 있습니다. 세로로 표시된 줄은 각각 평균 값을 의미하고, 오른쪽에는 median SV counts를 표현합니다.
(용어) Super-population ancestry 표기: EUR(유럽인); AFR(아프리카인); EAS(동아시아인); SAS(서아시아인); AMR(아메리카인); Structural Variant 종류 표기: DEL(deletion); DUP(duplication); mCNV(multiallelic CNV); INS(insertion); INV(inversion); CPX(complex SV); CTX(inter-chromosomal translocation)

[Figure 3] small variant call과 phase 3 call set 간의 비교
(A, B) phase 3의 2,504개의 샘플 및 high-coverage dataset에서 보유하는 SNV 수 (B) INDEL 수의 요약입니다. AF bins, genome region에 의해 나누었습니다.
(C, D) FDR(False Discovery Rate)의 비교 ((C) SNV, (D) INDEL) 입니다. AF bins, genome region에 의해 나누었습니다. GIAB truth set에 의해 정의된 easy & difficult region 모두 새로운 버전의 1000 Genome Project에서 FDR이 낮아, 실제로 SNV이나 INDEL이 아닌데도 그렇게 분류하는 경우가 줄어든 것을 확인할 수 있습니다.
(E, F) Sample-level (E) SNV, (F) INDEL 수입니다. 1kGP super-population ancestry에 의해 나누었습니다.
(G, H) 예측된 functional (G) SNV, (H) INDEL 수입니다. y축에 Log2값을 취하여 variant count의 비율을 표현했습니다.
위: 코호트 단계 비교
중간: 샘플 단계 비교
아래: FDR 비교
빨간 별은 샘플 NA12878에 100개 미만의 샘플이 있음을 의미합니다. (이 경우, FDR estimation의 신뢰도가 낮아집니다.)
(C), (D), (G), (H)의 FDR은 GIAB truth set v3.3.2.에 따라 sample NA12878을 대상으로 진행했습니다.
(A), (B), (E-H)는 상염색체만을, (C), (D)는 성염색체도 포함하여 분석했습니다.

[Figure 4] ensemble SV calls와 phase 3 call set의 비교
(A) 서로의 structural variant call set가 얼마나 겹치는지 확인할 수 있는 그림입니다. SV에 관련된 각 데이터셋(ALL, DEL, DUP, INS, INV)의 SV count도 확인할 수 있습니다.
(B) 샘플 당 SV counts의 분포를 표현하며, 각 샘플 별 및 통합 call set에서의 겹치는 부분을 표현했습니다.
(C) 양쪽 데이터셋 모두에서 SV에 의해 변화한 gene의 수를 표현합니다.
pLOF(predicted loss of function); CG(complete copy gain); IED(intragenic exon duplication)
(D) Ancestral population 별로, SV에 의해 변화한 gene의 수를 표현합니다.

[Figure 5] Small variant 단계 생성 및 imputation 성능
(A) Small variants 중 조건(chr1-22, X; variant counts로 표현한 상위 10가지의
조건 조합을 나타냈습니다.)을 통과한 개수를 표현했습니다. (PASS:
VQSR을 통과한 sites; Miss.: genotype missingness;, HWE:
Hardy-Weinberg Equilibrium exact test, 1kGP super-population 중 최소 20%가 p-value > 1e-10인 small variants; MAC: Minor allele count)
위에서 ‘조건’이라 함은, haplotype phasing 과정에서 imputation에 사용할
수 있는 확실한 SNV/INDEL/SV call을 구성하는 데 reference
panel이 될 수 있는 데이터셋을 구성하기 위한 small variants set을 만드는
과정에 들어가는 일종의 quality control 입니다.
(B) High-coverage & phase 3 1kGP panel 간의
Haplotype phasing accuracy 비교값. (SER: switch
error rate – Platinum Genome truth set와 관련된 수치.) 두
가지의 추가적인 phasing condition(점선 표현 부분)은
평가 목적을 위한 high-coverage panel입니다.
(1) diamonds: NA12878 phasing 중 얻은 SER 수치. 코호트에 부모 정보가 없음.
(2) triangles: NA12878 phasing 중 얻은 SER 수치. 코호트에 부모님이 있지만, pedigree-based
correction(duohmm)이 적용되지 않은 데이터.
(C) High-coverage panel의 haplotype phasing accuracy. 샘플 간 연관성을 토대로 나누었습니다. HGSVC SNV call set와 연관지어 SER이 계산되었습니다.
(D) SNV, INDEL genotype의 imputation 정확도. High-coverage panel을 사용하여
imputation했으며, genomic region에 의해
나누었습니다. 110 SGDP 샘플에 비해 Mean r2,
squared Pearson correlation coefficient가 평균적으로 높았습니다.
(E) High-coverage 및 phase 3 panel 간의 imputation accuracy 비교입니다. Super-population ancestry에 의해 나누었습니다. 두
panel 간의 성능 비교는 공유되는 site에만 진행되었습니다.
(B-E)는 모두 상염색체 기준의 결과입니다.

[Figure 6] SV phasing 및 imputation performance
(A) 통합 haplotype-resolved panel에 포함된 filtered SV의 코호트 단계 개수입니다. SV type에 의해 나뉘어 표현되었습니다.
(B) Sample-level phased HET DEL 및 INS에 대한 분포입니다. HGSVC truth set와 비교하여 phasing accuracy를 계산했습니다.
(C) Sample-level phased HET SV의 parental flip rate의 분포입니다.SV type으로 나누어 보았습니다.
(D) High-coverage panel의 SV imputation performance를 SGDP study dataset에 적용했으며, 분류는 SV type에 따라 나누었습니다. Imputed allele dosage 간 mean r2, squared Pearson correlation coefficient 값, 그리고 SV truth set로부터 온 dosage를 계산해 본 결과, 110 SGDP 샘플의 평균보다 높았습니다. (AF = 0.5% bin: 100 , 92개 샘플의 INS, DEL의 결과는 위 내용에서 제외입니다.)
(E) SGDP study dataset에서 imputation된 SV의 수를 표현합니다. 3개의 MAF bin에 대해 High-coverage reference panel은 다음과 같습니다. (왼: info > 0.4, 오: info > 0.8, 110개의 imputated SGDP sample 대상의 MAF)
(B-E): 상염색체 대상으로 진행했습니다.
Disscussion
뉴런은 배아의 뇌 발달 초기에 대량으로 생성되지만 그 중 상당 부분이 후속 발달 단계에서 제거됩니다. 이러한 세포의 제거는 매우 선택적이어야 하며 따라서 외부 및 내부적으로 구동되는 프로세스를 통합할 수 있는 엄격한 메커니즘에 의해 규제되어야 합니다. 이 과정을 지시하는 요인에 대한 완전한 견해는 아직 없지만, 문헌은 신경 활동이 회로의 신경 통합의 척도로 사용될 수 있으므로 주산기 네트워크의 개선을 결정하는 요인이라고 제안합니다. 그러나 잠재적인 상류 신호 전달과 이 현상을 결정하는 신경 활동의 패턴은 불분명합니다. 정제 과정을 방해하면 뇌 회로에 영구적으로 영향을 미칠 수 있기 때문에 이 발달 단계에서 신경 속성을 조절할 수 있는 외인성 및 내인성 요인을 식별하는 것이 중요합니다.
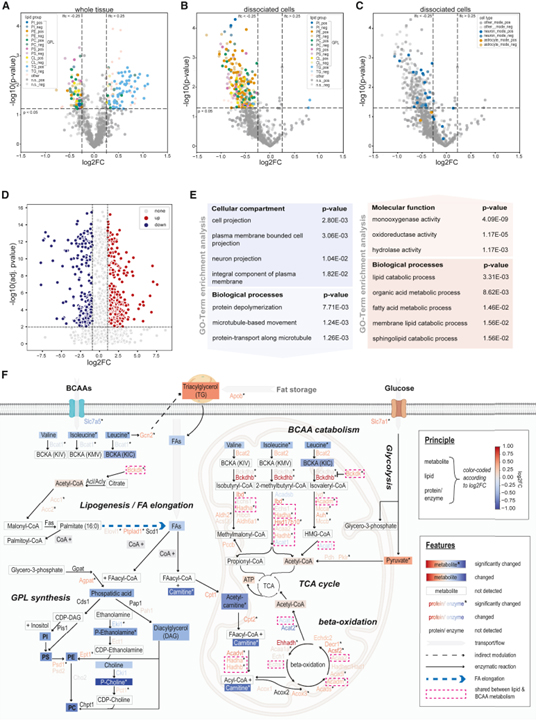
여기에서 우리는 뉴런의 본질적인 적합성과 대뇌 피질 회로에서의 통합을 결정하는 척도로서 대뇌 피질의 신경 세포의 대사 프로그램에 중점을 두었습니다. 신진대사는 세포 적합도의 중요한 요소이지만 시간이 지남에 따라 전뇌에서 다양한 대사 산물의 수준이 어떻게 변하는지에 대한 자세한 설명은 없습니다. 다양한 발달 단계에서 피질의 대사 프로필을 얻음으로써 우리는 이 뇌 영역에서 감지된 대사 산물과 발달 과정에 따른 변화에 대한 포괄적인 관점을 제공합니다. 여러 대사 산물이 신경 발달 상태와 연결되어 있기 때문에 우리의 데이터는 뇌 장애와 관련하여 잠재적인 중요한 시간 창을 평가하는 데 중요할 수 있습니다. 예를 들어, 우리의 분석은 필수적인 LNAA에 대한 하향 궤도를 강조했으며, 그 수준은 주산기의 대뇌 피질에서 상당히 감소했습니다. 돌연변이가 자폐증과 소두증을 유발하는 LNAA 수송체인 Slc7a5를 삭제함으로써 우리는 신경 세포의 대사 및 생리학적 상태에 대해 이러한 AA를 조절하는 것의 중요성을 테스트했습니다. 우리는 SLC7A5 발현이 주산기 단계에서 피질 뉴런의 대사 상태를 지정하는 데 결정적인 요인임을 발견했습니다. 이러한 맥락에서 뉴런의 Slc7a5 전사가 태아가 출생 중 및 출생 직후에 경험하는 생리학적 상태인 저산소증에 의해 유도된다는 것을 관찰하는 것은 흥미로울 것입니다. 이 개발 기간 동안 SLC7A5 기판의 일반적인 수준이 충족되지 않으면 어떻게 됩니까? 우리는 BCAA의 감소된 수준이 지질 대사 장애와 결합되어 있다고 보고합니다. 이전 연구에서는 일부 세포 유형 및 병리학적 상태에서 BCAA와 지질 사이의 연결을 제안했습니다. Slc7a5가 없는 상태에서 우리가 관찰한 분자 재프로그래밍의 정확한 트리거는 아직 조사되지 않았지만, 우리의 분석은 신경 세포에서 두 경로가 밀접하게 연결되어 있음을 보여줍니다. 또한, 우리의 결과는 주 산기 단계의 뉴런이 BCAA를 ATP 생산의 주요 공급원으로 사용함을 나타냅니다. 이것은 이 단계에서 Slc7a5 발현의 급증과 미성숙 뉴런에서 미토콘드리아 피루브산 수송체의 필요 없음을 설명할 것입니다. 또한, Slc7a5 결실은 신경 흥분성의 세포 자율적 변화로 이어져 신경 네트워크에서의 통합과 세포의 적합성을 결합하는 우아한 예를 제공합니다. 우리의 모자이크 분석은 본질적인 흥분이 이 발달 단계에서 신경 생존 확률에 직접적으로 영향을 미칠 수 있음을 시사합니다. 감소된 신경 흥분성의 기본이 되는 정확한 메커니즘은 불분명합니다. 우리의 transcriptomic 분석은 Slc7a5 결핍 뉴런에서 이온 채널 발현의 변화를 밝히지 못했습니다. 그러나 우리의 proteomics 데이터는 주 산기 돌연변이 마우스에서 막 관련 팔미 토일 화 단백질의 변화를 나타냅니다. 따라서 가장 그럴듯한 설명은 Slc7a5 결핍 세포에서 관찰되는 지질 프로파일의 변화가 신경 흥분성과 관련된 이온 채널의 다른 클러스터링 및 변조를 초래한다는 것입니다. 또한 특정 GPL 하위 클래스 비율의 변화는 유동성 및 곡률과 같은 막 특성에 영향을 줄 수 있으며 이는 신경 흥분성을 추가로 조절할 수 있습니다.
전반적으로, 우리의 분석은 신경 발달을 위한 필수 AA와 같은 식이 획득 요인의 중요성을 강조합니다. SLC7A5 돌연변이가 있는 쥐와 인간에서 관찰된 소두증 발병의 유사한 궤적은 우리의 대사 프로필이 쥐 뇌의 변화를 설명하지만 인간과 쥐가 시간이 지남에 따라 유사한 대사 프로그램을 사용할 수 있음을 시사합니다. 또한, 관찰된 표현형의 단계 및 세포 유형 특이성은 뇌 발달의 특정 단계에 영향을 미칠 수 있고 인간 신경 발달 조건의 기본이 되는 유전적 요인과 상호 작용할 수 있는 환경, 대사 관련 요인을 평가하는 종단 연구 수행의 중요성을 지적합니다.