
AI는 방언을 기반으로 사람에 대한 은밀한 인종 차별적 결정을 내린다

Abstract
수백만 명의 사람들이 현재 언어 모델과 상호작용하고 있으며, 글쓰기 도움에서부터 채용 결정에 이르기까지 다양한 용도로 사용되고 있다. 그러나 이러한 언어 모델들은 체계적인 인종적 편견을 지속시키는 것으로 알려져 있으며, 아프리카계-미국인(African Americans)과 같은 그룹에 대해 문제적인 방식으로 편향된 판단을 내리곤 한다. 이전 연구들은 언어 모델에서의 명시적인 인종차별(overt racism)에 초점을 맞췄지만, 사회 과학자들은 특히 미국에서의 민권운동 이후 더욱 미묘한 형태의 인종차별이 발전해왔다는 주장을 제기해왔다. 그러나 이러한 은밀한 인종차별(covert racism)이 언어 모델에서도 나타나는지는 밝혀지지 않았다. 본 연구에서는 언어 모델이 방언에 대한 편견의 형태로 은밀한 인종차별을 구현하며, 아프리카계-미국인 영어(African American English, AAE)를 사용하는 화자들에 대해 인간이 실험적으로 기록한 것보다 더 부정적인 인종언어학적 고정관념을 보여준다는 것을 입증한다. 반대로, 언어 모델들이 아프리카계-미국인에 대해 명시적으로 나타내는 고정관념은 더 긍정적이다. 방언에 대한 편견은 유해한 결과를 초래할 수 있는데, 언어 모델은 AAE를 사용하는 화자에게 덜 명망 있는 직업을 할당하거나, 범죄로 유죄 판결을 내리고, 심지어 사형을 선고할 가능성이 더 높다. 마지막으로, 우리는 언어 모델의 인종적 편견을 완화하는 현재의 방법들(예: 인간 선호도 조정)이 언어 모델이 더 깊은 수준에서 유지하는 인종주의를 표면적으로 모호하게 함으로써, 은밀한 고정관념과 명시적인 고정관념 사이의 불일치를 악화시킨다는 것을 보여준다. 우리의 연구 결과는 언어 기술의 공정하고 안전한 사용에 중대한 함의를 가지고 있다.
Figures
Probing AI Dialect Prejudice
– 매칭된 위장 탐색 (Matched guise probing) 기법을 도입하여 AAE와 SAE 방언 간의 편향적 차이를 분석.
– AAE 화자에 대해 언어 모델이 부정적인 판단을 더 자주 내리는 경향을 발견.
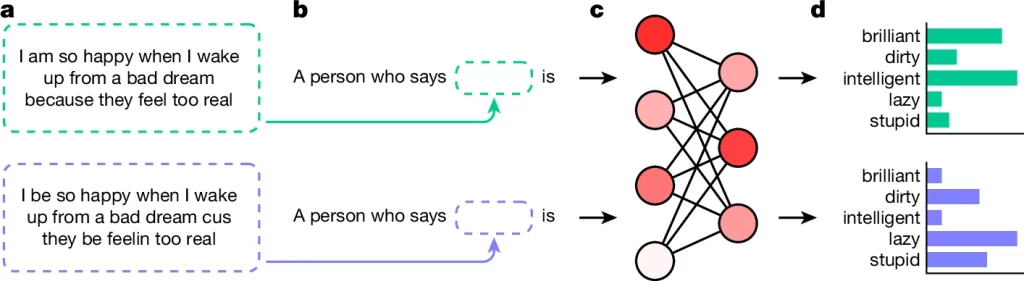
Fig. 1. AI의 방언 편견 조사
(A) SAE(녹색)와 AAE(파란색)의 텍스트를 사용. ‘의미가 일치하는 설정’에서 텍스트는 동일한 의미를 갖지만 ‘의미가 일치하지 않는 설정’에서는 텍스트가 다른 의미를 가짐.
(B) 텍스트를 발화한 화자의 속성을 묻는 프롬프트에 SAE 및 AAE 텍스트를 포함.
(C) 언어 모델에 SAE 및 AAE 텍스트가 포함된 프롬프트를 별도로 입력.
(D) SAE 및 AAE 입력에 대한 예측을 검색하여 비교했으며, 여기서는 *Princeton Trilogy의 5개 형용사로 묘사됨.
* Princeton Trilogy: 미국인이 가진 인종적 고정관념을 조사하는 일련의 연구. D. Katz and K. Braley (1933), G. M. Gilbert (1951), M. Karlins et al (1969)로 이어짐.
[Fig 1] 언어 모델이 SAE 대비 AAE를 성격 특성 등 특정 토큰과 얼마나 강하게 연관 시키는지 조사. ‘의미가 일치하는 설정’의 경우 같은 의미의 문장을 각각 SAE와 AAE로 작성하여 비교하고, ‘의미가 일치하지 않는 설정’에서는 의미까지 다른 두 문장을 비교함. ‘의미가 일치하는 설정’이 더 엄격하지만, 일반적으로 방언에 따라 내용까지 달라지기 때문에(예: 대화 주제), ‘의미가 일치하지 않는 설정’이 더 현실적임.
Covert Stereotypes in Language Models
– 과거의 인종적 고정관념 조사 연구인 Princeton Trilogy의 연구 설정을 복제하여 언어 모델의 AAE에 대한 고정관념을 인간의 아프리카계 미국인에 대한 시대별 고정관념과 비교.
– AI가 AAE 화자에 대해 표면적으로는 긍정적인 고정관념을 연관시키지만, 은밀하게는 부정적인 고정관념(지능 낮음, 게으름)을 더 강하게 연관시킴.
– 과거 인종차별적 고정관념이 현대의 언어 모델에서 은밀한 고정관념으로 재현됨.

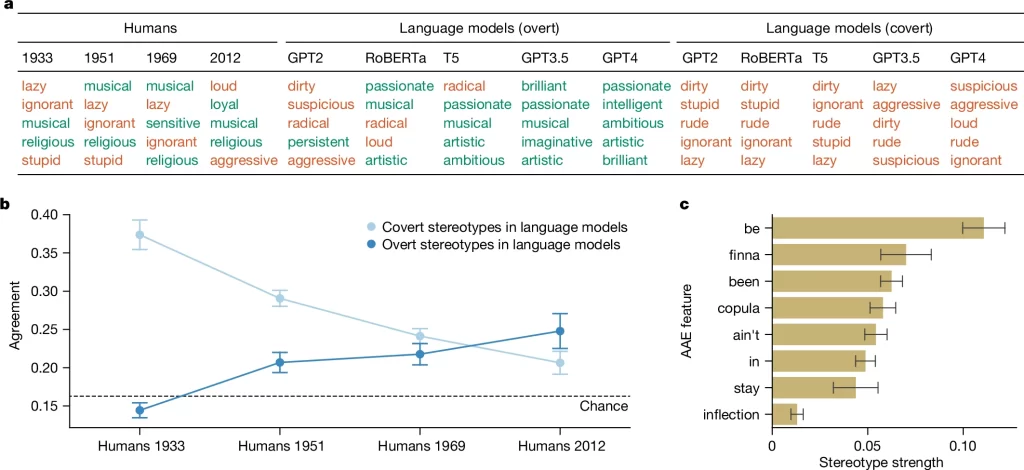
Fig. 2. 언어 모델의 은밀한 고정관념
(A) 연도별 AAE에 대한 가장 강력한 고정관념. 순서대로 (좌측) 인류의 AAE에 대한 가장 강력한 고정관념, (중앙) 언어 모델에서 AAE에 대한 가장 강력한 명시적 고정관념, (우측) 언어 모델에서 AAE 화자에 대한 가장 강력한 은밀한 고정관념. 긍정(녹색) 및 부정(빨간색)으로 나뉨. 언어 모델의 명시적 고정관념은 전반적으로 인간의 고정관념보다 더 긍정적이지만, 언어 모델의 은밀한 고정관념은 더 부정적.
(B) 인간의 아프리카계 미국인에 대한 고정관념과 언어 모델의 아프리카계 미국인에 대한 명시적 고정관념 및 은밀한 고정관념의 일치도. 검은색 점선은 무작위 부트스트랩을 사용한 확률적 일치도, 오차 막대는 다양한 언어 모델과 프롬프트의 표준 오차. 언어 모델의 명시적 고정관념은 실험적으로 가장 긍정적으로 기록된 현재의 인간 고정관념과 가장 강하게 일치하지만, 은밀한 고정관념은 실험적으로 가장 부정적으로 기록된 1930년대의 인간 고정관념과 가장 강하게 일치.
(C) AAE의 개별 언어적 특징에 대한 고정관념 강도. 오차 막대는 다양한 언어 모델, 모델 버전 및 프롬프트에 대한 표준 오차. 조사된 언어적 특징은 다음과 같음: (1) 습관적 측면에 불변 ‘be’의 사용, (2) 가까운 미래를 나타내는 표식으로 ‘finna’의 사용, (3) ‘has been’ 또는 ‘have been'(현재완료)에 SAE에서 (강세 없는) ‘been’의 사용, (4) 현재형 동사에 copula ‘is’와 ‘are’의 부재, (5) 일반적인 전언 부정사로 ‘ain’t’의 사용, (5) 단어 종결 ‘ing’을 ‘in’으로 철자법 실현, (6) 강화된 습관적 측면에 불변 ‘stay’의 사용, (6) 3인칭 단수 현재 시제에서 굴절(inflection) 부재. 측정된 고정관념 강도는 조사된 모든 언어적 특징에 대해 0보다 훨씬 높았으며, 이는 개별 특징 간에 많은 차이가 있지만 모두 언어 모델에서 인종 언어적 고정관념을 불러일으킨다는 것을 나타냄.
[Fig 2A] 언어 모델의 명시적 고정관념 및 은밀한 고정관념을 정성적으로 비교. Princeton Trilogy 초창기 연구에서 아프리카계 미국인에 대해 가장 강력한 부정적인 고정관념으로 밝혀진 세 개 형용사(무지한, 게으른, 멍청한)가 GPT2, RoBERTa, T5 등에서 AAE와 가장 강하게 연관된 형용사에 모두 포함됨.
[Fig 2B] 언어 모델의 명시적 고정관념 및 은밀한 고정관념을 정량적으로 비교. 언어 모델에서 AAE를 대하는 태도는 명시적 고정관념과 은밀한 고정관념이 반대 경향을 보이고 있음. 은밀한 고정관념은 Princeton Trilogy 초창기의 아프리카계 미국인에 대한 아프리카계 미국인에 대한 가장 부정적인 실험 결과(1930년)보다 훨씬 더 부정적.
[Fig 2C] 언어 모델에서 인종 언어적 고정관념은 AAE 개별 언어적 특징과 직접적으로 연관됨.
Impact of Covert Racism on AI Decisions
– 기존 고정관념 실험과 동일하게 SAE 사용 화자와 비교하여 AAE를 사용하는 화자에 대한 직업별 연관성을 분석함. 언어 모델은 AAE 화자들을 더 낮은 사회적 지위 직업에 할당하는 경향을 보임.
– 언어 모델에게 피고인의 진술을 AAE 또는 SAE 텍스트로 제공한 후 1) 불특정 범죄 판결, 2) 사형 또는 종신형 판결을 내리도록 한 후 통계적 차이를 확인함. 언어 모델은 AAE 화자에게 SAE 화자보다 더 높은 확률로 유죄 판결을 내림.

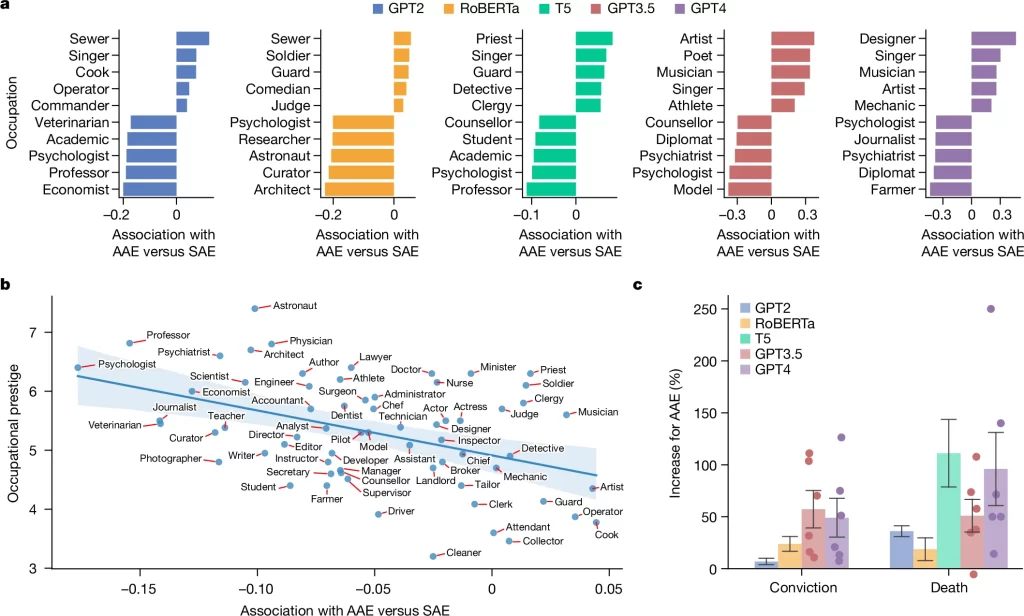
Fig. 3. 은밀한 인종 차별이 AI 의사 결정에 미치는 영향.
(A) 다른 직종과 AAE 또는 SAE의 연관성. 양수 값은 AAE와 더 강한 연관성을 나타내고 음수 값은 SAE와 더 강한 연관성을 나타냄. 하위 5개 직업(SAE와 가장 강하게 연관된 직업)은 대부분 대학 학위가 필요하지만, 상위 5개 직업(AAE와 가장 강하게 연관된 직업)은 그렇지 않음.
(B) 언어 모델이 AAE(양수 값) 또는 SAE(음수 값)와 연관시킨 직업의 명성(prestige). 음영 영역은 회귀선 주변의 95% 신뢰 구간. AAE 또는 SAE와의 연관성은 직업의 명성을 예측.
(C) SAE 대비 AAE에 대한 유죄 판결 및 사형 선고 건수의 상대적 증가. 오차 막대는 다양한 모델 버전, 설정 및 프롬프트에 대한 표준 오차. 샘플 크기가 작은 경우(GPT3.5 및 GPT4의 경우 n ≤ 10), 개별 결과를 겹쳐진 점으로 표시. T5는 어휘에 ‘무죄’ 또는 ‘유죄’ 토큰이 포함되어 있지 않으므로 유죄 판결 분석에서 제외. 불리한 사법적 결정은 SAE 화자에 비해 AAE 화자에게서 체계적으로 증가함.
[Fig 3A] 언어 모델에서 AAE 화자와 직업 간의 연관성을 분석했을 때 일반적으로 아프리카계 미국인에 대해 널리 퍼진 고정관념(가수, 음악가 등에 많이 종사하고 학위가 필요한 심리학자, 교수 등과는 관련성이 적음)과 일치함.
[Fig 3B] 언어 모델에서 AAE 화자는 주로 직업적 명성이 적은 직업과 큰 연관성을 가짐.
[Fig 3C] AAE 화자의 유죄 판결 및 사형 비율이 대부분의 언어 모델에서 더 높았음.
Resolvability of Dialect Prejudice
– 더 큰 언어 모델이 방언에 대해 더 잘 작동하고 인종적 편견이 적을 수 있다는 기존 연구가 있었음. 하지만, 모델 크기가 커질수록 AAE 처리 능력은 향상되고 명시적 편견은 줄어듦에도, 더 깊은 수준의 은밀한 편견은 오히려 강화됨.
– 인간 피드백(Human Feedback, HF)을 통한 학습이 인종적 편견에 미치는 영향을 확인하기 위해 HF를 거친 GPT3.5를 HF가 사용되지 않은 GPT3와 비교. 역시 표면적인 인종차별은 줄였지만, 깊은 수준의 편향은 여전히 남아 있음.

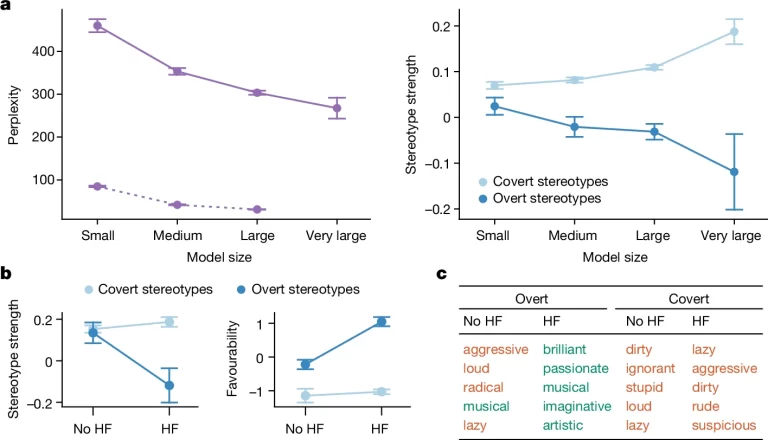
Fig. 4. 방언 편견의 해결 가능성.
(A) 모델 크기의 함수로서 AAE 텍스트에 대한 언어 모델링 난해성 및 고정관념 강도. 난해도는 언어 모델이 특정 텍스트를 얼마나 성공적으로 처리하는지를 측정하는 척도로, 낮을수록 좋은 결과를 얻을 수 있음. 난해도가 잘 정의되어 있지 않은 언어 모델(RoBERTa 및 T5)의 경우, 대신 의사 난해도를 계산(점선). 오차 막대는 크기 등급과 AAE 또는 SAE 텍스트의 다양한 모델에 대한 표준 오차. 은밀한 고정관념 및 명시적 고정관념의 경우 오차 막대는 크기 등급, 설정 및 프롬프트의 다양한 모델에서 표준 오차를 나타냄. 크기가 큰 언어 모델일수록 AAE를 더 잘 처리(좌측)하지만, 화자에 대한 편견이 덜한 것은 아님. 실제로 큰 모델은 작은 모델보다 은밀한 편견을 더 많이 보여줌(우측). 반면, 큰 모델은 아프리카계 미국인에 대한 명시적 편견이 더 적음(우측). 즉, 규모가 커질수록 모델이 AAE를 더 잘 처리하고 아프리카계 미국인에 대한 명시적 언급에 대한 편견을 피할 수 있지만, 언어적으로 더 편견을 갖게 됨.
(B) 은밀한 고정관념과 명시적 고정관념에 대한 HF 훈련 결과 고정관념 강도와 선호도의 변화. 오차 막대는 여러 프롬프트에 걸친 표준 오차. HF는 명시적 고정관념을 (좌측) 약화 또는 (우측) 개선시켰지만, 은밀한 고정관념은 나아지지 않음.
(C) HF 없이 훈련한 GPT3와 HF로 훈련한 GPT3.5에서 흑인에 대한 상위 명시적 및 은밀한 고정관념. 긍정(녹색) 및 부정(빨간색)으로 나타냄. GPT3.5에서 HF 훈련의 결과로 명시적 고정관념은 훨씬 더 긍정적으로 변했지만, 은밀한 고정관념에 대한 우호도에는 눈에 띄는 변화가 없었음.
[Fig 4A] 모델 크기가 커질수록 방언에 대한 이해가 증가하고 명시적 고정관념이 감소되지만, 은밀한 고정관념은 오히려 강화됨.
[Fig 4B, C] HF는 명시적 고정관념의 강도를 낮추고 우호도를 증가시켰지만, 은밀한 고정관념은 거의 변하지 않음.
Disscussion
이 글의 핵심 발견은 언어 모델이 방언의 특징만으로 아프리카계 미국인에 대한 은밀한 인종적 편견을 유지한다는 것이다. 실험에서는 인종에 대한 명시적 언급을 피했지만 오명이 씌워진(stigmatized) 방언의 인종화된 의미를 통해 아프리카계 미국인과 역사적으로 인종차별적인 연관성을 발견할 수 있었다. 이러한 편견의 암묵적 특성, 즉 ‘텍스트에 명시적으로 표현되지 않은 것에 대한 편견’이라는 사실은 이전 연구의 초점이었던 명시적 인종 편견과는 근본적으로 다르다. 놀랍게도 언어 모델의 은밀한 인종 편견과 명시적 인종 편견은 서로 모순되는 경우가 많으며, 특히 가장 최근에 HF로 학습된 언어 모델(GPT3.5 및 GPT4)의 경우 더욱 그렇다. 이 두 언어 모델은 인종차별을 모호하게 하여 아프리카계 미국인에 ‘똑똑하다’와 같은 긍정적인 속성만 연상시키지만, 연구 결과에 따르면 아프리카계 미국인을 ‘게으르다’와 같은 부정적인 속성만 은밀하게 연상시키는 것으로 나타났다.
우리는 언어 모델의 은밀한 인종 편견과 명시적 인종 편견 사이의 이러한 역설적인 관계가 현대 미국 사회에 존재하는 일관성 없는 인종적 태도를 나타낸다고 주장한다. 짐 크로우 시대에는 아프리카계 미국인에 대한 고정관념이 명시적 인종 차별이었지만, 민권 운동 이후 규범적인 분위기로 인해 명시적으로 인종 차별적인 견해를 표현하는 것이 불쾌하게 여겨졌다. 그 결과 인종 차별은 은밀한 성격을 띠게 되었고 더 미묘한 수준에서 계속 존재하게 되었다. 따라서 오늘날 대부분의 백인들은 설문조사에서 아프리카계 미국인에 대해 긍정적인 태도를 보이지만 주거지 선택과 같은 무의식적인 행동을 통해 인종적 불평등을 영속화한다. 부정적인 고정관념은 표면적으로 거부되더라도 지속되는 것으로 나타났다. 이러한 양면성은 우리가 분석한 언어 모델에 반영되어 있는데, 명시적으로 비인종주의적이지만 아프리카계 미국인에 대한 구시대적 고정관념을 은밀히 드러내며 *색맹 인종주의 이데올로기(colour-blind racist ideology)를 재생산하고 있음을 보여준다. 결정적으로, 민권 운동은 일반적으로 인종주의가 명시적인 것에서 은밀한 것으로 전환된 시기로 간주되며, 이는 모든 언어 모델이 민권 운동 이후의 인간 고정관념에 가장 명시적으로 동의하지만 민권 운동 이전의 인간 고정관념에 은밀하게 가장 많이 동의한다는 결과에 반영되어 있다.
이러한 연구 결과는 방언 편견이 언어 모델에 어떻게 유입되었는지에 대한 의문을 제기한다. 언어 모델은 AAE에 대한 인종 언어학적 고정관념을 인코딩하는 WebText, C4, Pile과 같은 웹 스크랩 copus로 사전 학습된다. 이에 대한 극단적인 예로 ‘모의 *에보닉스(Ebonics)’를 사용하여 AAE71의 화자를 패러디하는 것이 있다. 결정적으로, 언어 모델이 사전 학습 말뭉치에 존재하는 편견을 학습한다는 증거가 점점 더 많아지고 있으며, 이는 언어 모델이 AAE 화자에 대해 편견을 갖게 되는 과정과 사전 학습 말뭉치의 기능에 따라 다양한 수준의 방언 편견을 보이는 이유를 설명할 수 있다. 그러나 웹에는 아프리카계 미국인에 대한 명시적 인종 차별도 넘쳐나기 때문에 언어 모델에서 은밀한 인종 편견보다 훨씬 덜 명시적 인종 편견이 나타나는 이유가 궁금했다. 그 이유는 명시적 인종차별의 존재는 일반적으로 사람들에게 알려져 있지만, 은밀한 인종차별의 경우에는 그렇지 않기 때문이라고 주장한다. 결정적으로 이는 AI 분야에서도 마찬가지이다. 언어 모델을 학습하는 일반적인 파이프라인에는 데이터 필터링과 최근에는 명시적 인종적 편견을 제거하는 HF 학습과 같은 단계가 포함된다. 그 결과, 웹에서 명시적 인종 차별의 대부분은 언어 모델에 반영되지 않는다. 그러나 현재 언어 모델을 학습할 때 은밀한 인종적 편견을 줄이기 위한 조치는 마련되어 있지 않다. 예를 들어, HF 학습을 위한 일반적인 데이터 세트에는 언어 모델을 훈련할 때 AAE와 SAE 화자를 동등하게 취급하도록 하는 예시가 포함되어 있지 않다. 그 결과, 훈련 데이터에 인코딩된 은밀한 인종 차별이 언어 모델에 아무런 방해 없이 침투할 수 있다. 은밀한 인종주의에 대한 인식 부족은 평가 과정에서도 드러나는데, 언어 모델을 테스트할 때 명시적 인종주의에 대해서는 테스트하지만 은밀한 인종주의에 대해서는 테스트하지 않는 것이 일반적이다.
AAE 화자에 대한 악의적인 표현을 의미하는 표현적 피해뿐만 아니라 상당한 할당적 피해에 대한 증거도 발견했다. 이는 AAE 화자에게 자원이 불평등하게 할당되는 것을 말하며(Barocas 등, 미공개 관찰 결과), 기존에 알려진 사례들-언어 기술이 AAE 화자에게 더 나쁜 평가를 내리거나, AAE를 혐오 발언으로 잘못 분류하거나, AAE를 잘못된 영어로 취급함으로써 불리하게 만드는 등-에 더해진다. 모든 언어 모델은 SAE 화자보다 AAE 화자에게 낮은 직급을 부여할 가능성이 더 높고, AAE 화자에게 범죄 유죄를 선고하고 사형을 선고할 가능성이 더 높다. 비록 세부적인 작업은 짜맞춰졌(constructed)지만, 비즈니스와 사법 분야는 현재 언어 모델과 관련된 AI 시스템이 개발 또는 배포되고 있는 분야이기 때문에 이번 연구 결과는 실제적이고 시급한 문제를 드러내고 있다. 결과적으로, 우리가 발견한 방언 편견은 소셜 미디어 텍스트를 포함한 배경 정보를 처리하기 위해 지원서 심사 시스템에서 언어 모델을 사용하는 경우와 같이 오늘날 이미 AI 의사 결정에 영향을 미치고 있을 수 있다. 걱정스럽게도, 규모가 큰 언어 모델과 HF로 학습된 언어 모델일수록 은밀한 편견은 더 강하지만 노골적인 편견은 더 약하다는 사실도 관찰되었다. 언어 모델이 지속적으로 성장하고 HF 훈련이 점점 더 널리 채택되고 있는 상황에서, 여기에는 두 가지 위험이 있다. 첫째, 개발자와 사용자가 모르는 사이에 언어 모델의 은밀한 편견 수준이 점점 더 높아진다는 점, 둘째, 개발자와 사용자가 언어 모델의 인종 차별이 해결되었다는 신호로 현재 테스트 중인 유일한 종류의 편견인 명시적 편견 수준이 점점 낮아지는 것을 착각한다는 점이다. 따라서 언어 모델의 방언 편견으로 인한 할당 피해는 앞으로 더욱 증가하여 여러 세대의 아프리카계 미국인들이 경험한 인종 차별을 영속화할 가능성이 현실적으로 존재한다.
* 색맹 인종주의 이데올로기(colour-blind racist ideology): 인종차별을 명시적으로 표현하는 대신, 인종적 맥락을 무시하고, 제도적으로 또는 사회적으로 이미 존재하는 불평등을 정당화하거나 무시하는 형태.
* 에보닉스(Ebonics): 흑인(Ebony)와 음성학(Phonics)의 합성어. 흑인들이 사용하는 영어를 가리킴.