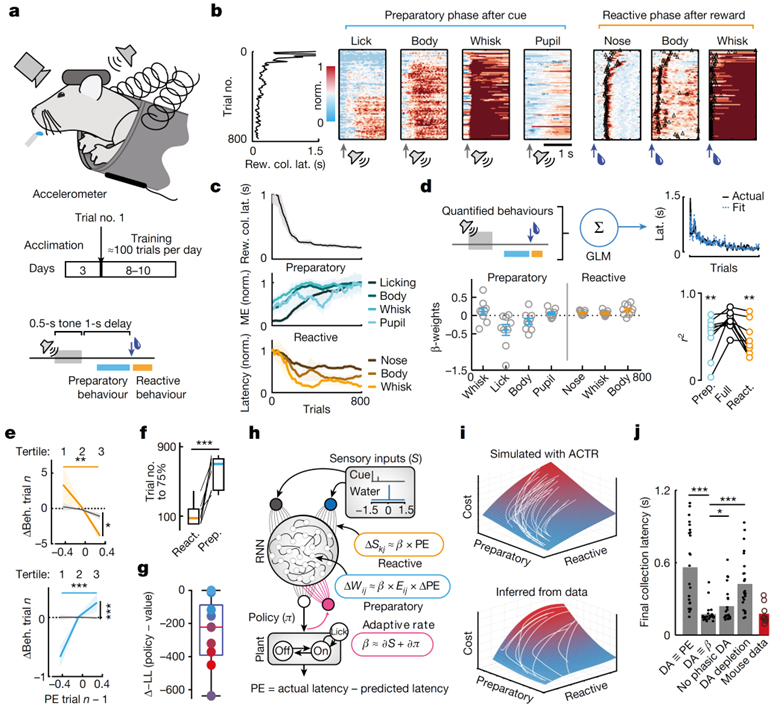
최근 인공 에이전트 및 로봇 교육의 성공은 행동 정책의 직접 학습과 가치 기능을 통한 간접 학습의 조합에서 비롯됩니다. 정책 학습과 가치 학습은 각각 행동 성과와 보상 예측을 최적화하는 별개의 알고리즘을 사용합니다. 동물에서 행동 학습과 mesolimbic 도파민 신호의 역할은 보상 예측과 관련하여 광범위하게 평가되었습니다. 그러나 지금까지 직접적인 정책 학습이 우리의 이해에 어떻게 영향을 미칠 수 있는지에 대한 고려는 거의 없었습니다.
이 연구에서는 행동 정책이 순진하고 머리가 제한된 쥐가 추적 컨디셔닝 패러다임을 배웠을 때 어떻게 진화했는지 이해하기 위해 orofacial 및 신체 움직임의 포괄적인 데이터 세트를 사용했습니다. 초기 도파민성 보상 반응의 개인차는 학습된 행동 정책의 출현과 관련이 있지만 예측 단서에 대한 추정 가치 인코딩의 출현은 아닙니다. 마찬가지로 중변연계 도파민의 생리학적으로 보정된 조작은 가치 학습과 일치하지 않는 몇 가지 효과를 생성했지만 행동 정책 학습을 위한 오류 신호가 아닌 적응 속도를 설정하기 위해 도파민 신호를 사용하는 신경망 기반 모델에 의해 예측되었습니다.
이 작업은 단계적 도파민 활동이 행동 정책의 직접 학습을 조절할 수 있다는 강력한 증거를 제공하여 동물 학습을 위한 강화 학습 모델의 설명력을 확장합니다.